AI 推斷加速
- 最低時延的 AI 推斷
- 加速整體應用
- 匹配 AI 創新的速度

具有最低時延的 AI 推斷

高吞吐量或低時延
使用大批量可實現吞吐量。您必須等到所有輸入準備就緒後再進行處理,這不可避免地增加了延遲。
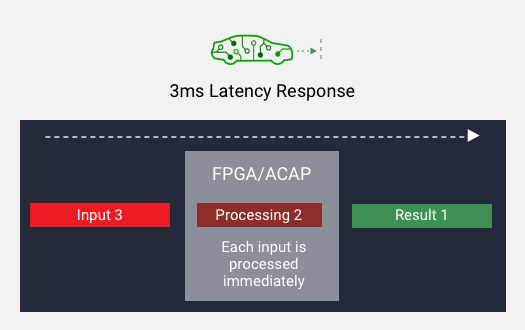
高吞吐量和低時延
使用小批量可實現吞吐量。在每個輸入準備就緒後即可開始處理,從而降低了延遲。
加速整體應用
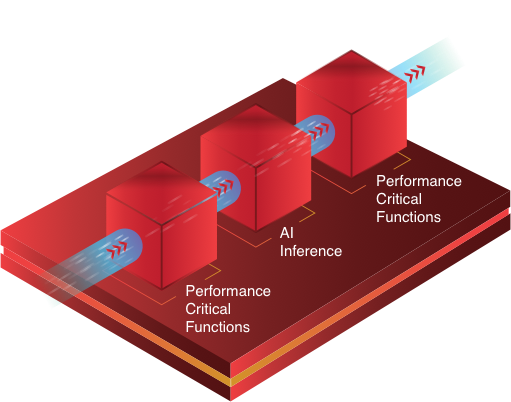
通過將自定義加速器與具有動態架構的芯片器件緊密耦合,可為 AI 推斷和其他關鍵性能功能優化硬件加速。
與固定架構的 AI 加速器(例如 GPU)相比,它可顯著提高整體應用性能。 而對於 GPU,應用的其他性能關鍵型功能必須在軟件中執行,而不具備自定義硬件加速的性能和效率優勢。
匹配 AI 創新的速度
人工智能模型正在迅速發展
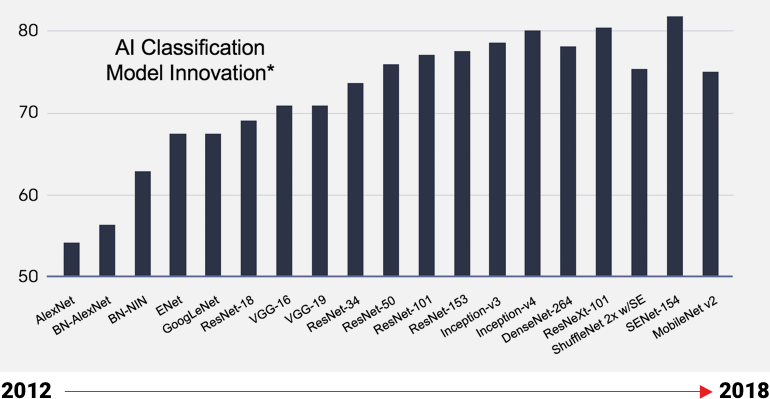
自適應芯片允許特定領域架構(DSA)更新,
無需新芯片,便可優化最新人工智能模型

固定矽器件的開發周期較長,因此尚未針對最新型號進行優化

數據中心的 Vitis AI
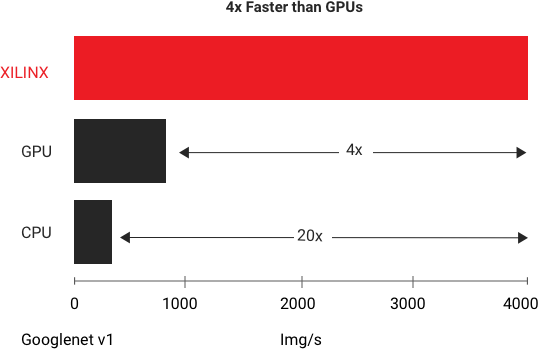
Xilinx 能提供最高的吞吐量和最低的時延。在 GoogleNet V1 上運行的標準基準測試中,Xilinx Alveo U250 平台在實時推斷中提供的吞吐量性能是最快 GPU 的四倍。 有關更多詳細信息,請參見白皮書:使用 Xilinx Alveo 加速器卡加速 DNN(中文版)
電子書:數據中心中的 AI
邊緣的 Vitis AI
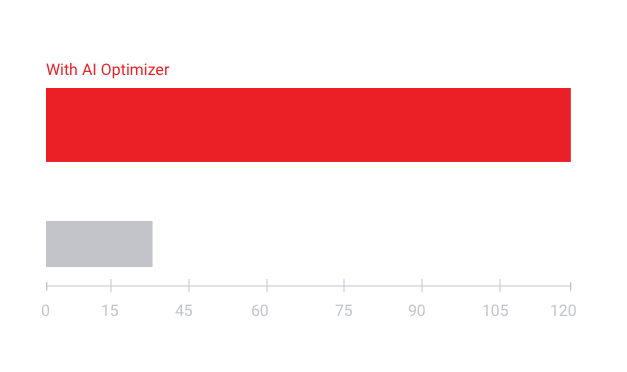
憑借 Vitis AI Optimizer 技術獲得 AI 推斷性能領先地位。
- 5 倍至 50 倍的網絡性能優化
- 改善幀率(FPS),降低功耗
優化/加速編譯器工具
- 支持 Tensorflow 和 Caffe 網絡
- 將網絡編譯為優化的 Xilinx Vitis 運行時