

為什麼選擇 Xilinx AI
最高計算效率和最佳性能
最佳 AI 推斷性能
從邊緣到數據中心的業界最高級 AI 加速。最高的 AI 推斷性能,最快的體驗和最低的成本。

麵向數據中心的 AI
以最低時延實現最高吞吐量,從而可加速雲端圖像處理、語音識別、推薦係統加速以及自然語言處理 (NLP) 加速

麵向邊緣的 AI
卓越的 AI 推斷功能,可加速在自動駕駛汽車、ADAS、醫療保健、智慧城市、零售、機器人以及邊緣自主機器中的深度學習處理。
限時特惠與 AI 網絡研討會
.jpg)
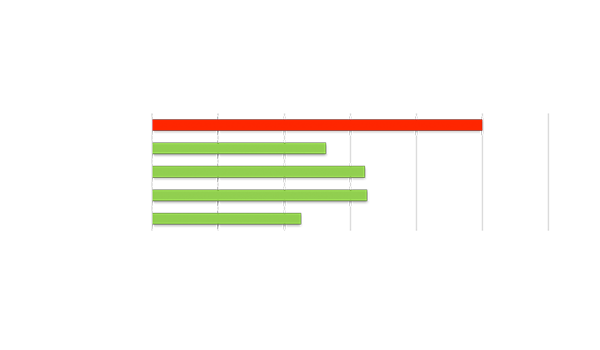
數據中心 AI 加速
高吞吐量 AI 推斷

高性能 AI 推斷
與主流 GPU 相比,TCO 提升 1 倍
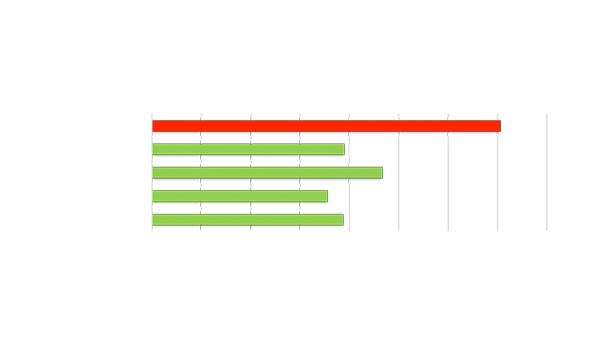

最高性能的視頻分析吞吐量
與主流 GPU 相比,視頻流數量增加 1 倍
")
簡易學習曲線
不需要硬件編程的普及型 AI 模型和框架

圖源:https://developer.Nvidia.com/deep-learning-performance-training-inference
Xilinx 數據中心 AI 案例研究



使用 Xilinx 數據中心 AI 解決方案啟動設計



購買 VCK5000
為在 Xilinx 7nm Versal ACAP 上構建的 AI 推斷購買 VCK5000 開發卡
在雲端試用 VCK5000
使用 Mipsology 執行高性能 AI 推斷計算,使用 Aupera 為 AI 識別實現全視頻處理 ML 推斷流水線
下載 Vitis AI
使用 Xilinx AI 解決方案啟動設計並下載 Vitis™ AI 開發環境
邊緣 AI 加速
業界領先的 AI 加速性能

具有最低時延的 AI 推斷
- Zynq® UltraScale+ 及 Versal® 上的最佳 FPS 和功耗
- 強大的深度學習處理單元 (DPU)
- 業界一流的模型優化技術;5 倍至 50 倍的模型性能提升

靈活的軟件流程
- 支持 PyTorch、TensorFlow 和 Caffe 的 AI 模型
- 基於 C++ 和 Python 的簡單庫和 API
- 支持跨邊緣平台部署的統一量化器、編譯器和運行時

可擴展與靈活應變
- 可擴展的 DPU IP 適用於不同的邏輯和 AIE 資源
- 開放式 AI 模型專區,可在開發板上免費試用
- 整體應用加速
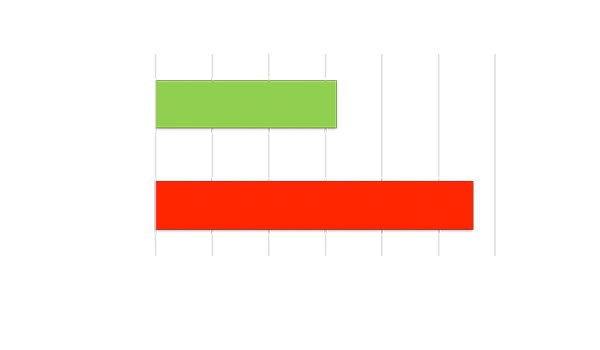
時延響應對比

高吞吐量或低時延
使用大批量規模實現吞吐量。在處理之前必須等待所有輸入就緒,從而導致高時延。

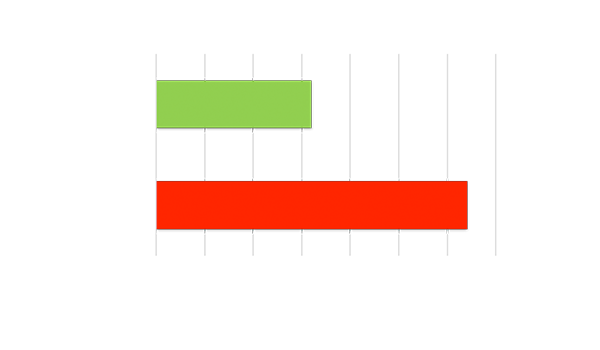
高吞吐量與低時延
使用小批量規模實現吞吐量。在每個輸入就緒時立即處理,從而降低時延。
適合所有邊緣现金网博e百 的可擴展性

端到端應用性能
將自定義加速器緊密耦合在動態架構芯片器件中,優化了 AI 推斷以及其它性能關鍵型功能的硬件加速。
這提供的端到端應用性能明顯高於固定架構 AI 加速器。在該器件中,沒有自定義硬件加速的性能或效率,應用的其它性能關鍵型功能仍然必須在軟件中運行。


利用 Xilinx 邊緣 AI 解決方案開始設計



購買 Kria KV260 視覺 AI 入門套件
針對高級視覺應用開發構建,無需複雜的硬件設計知識
下載 Vitis AI
使用 Vitis AI 在應用的邊緣設備上實現高效的 AI 計算
訪問 Xilinx 應用商城
Kria 係統級模塊 (SOM) 的預構建應用評估、購買和部署加速應用!
探索 Xilinx 的邊緣 AI 推斷解決方案




真人百家乐游戏开户 資源

訪問 Xilinx 應用商城
評估、購買和部署加速應用!

真人百家乐游戏开户 網站
仔細研究技術文章、項目和教程等!

及時了解最新信息
關注所有有關 AI 加速的新聞